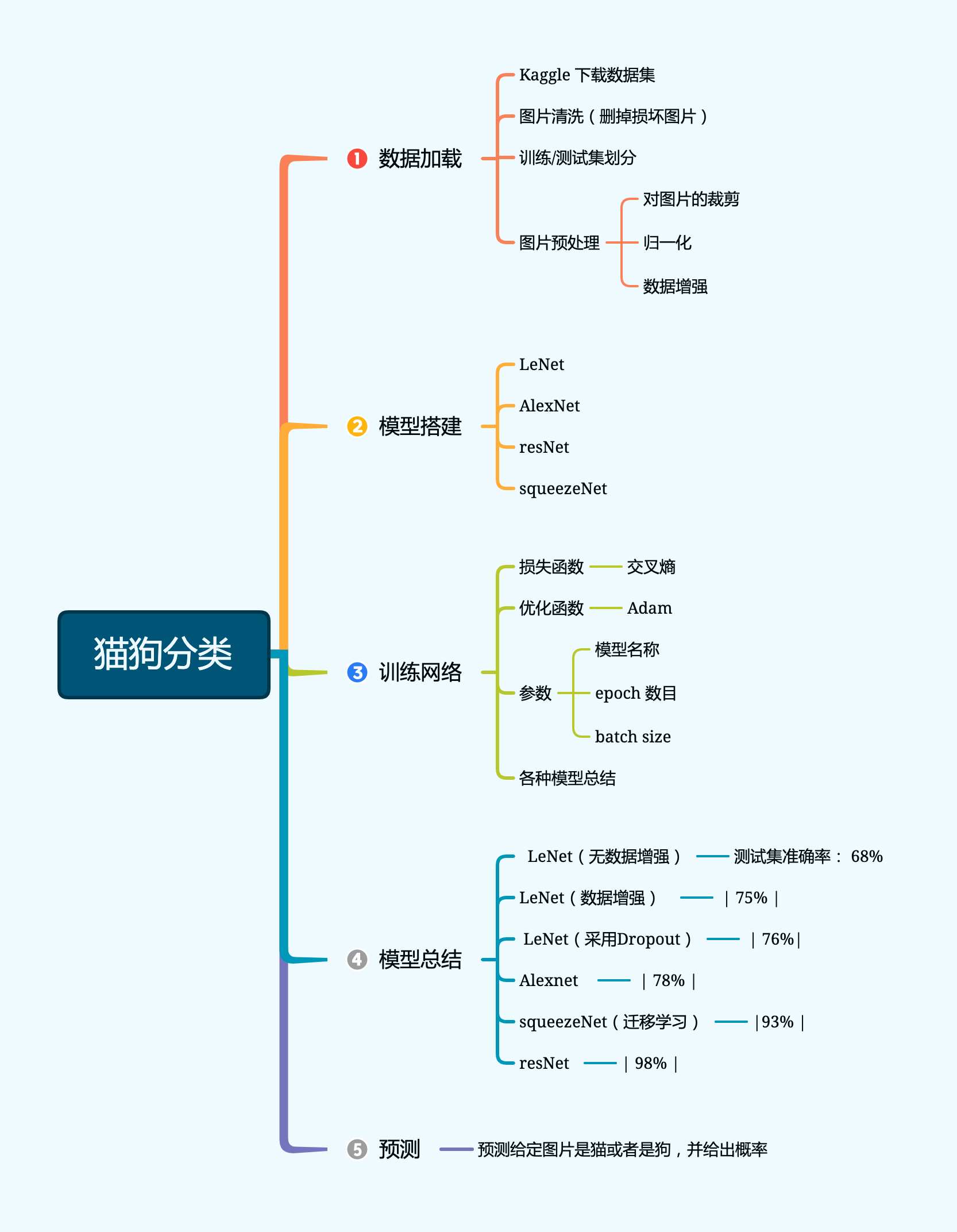
猫狗分类来源于Kaggle上的一个入门竞赛——Dogs vs Cats。为了加深对CNN的理解,基于Pytorch复现了LeNet,AlexNet,ResNet等经典CNN模型,源代码放在GitHub上,地址传送点击此处。项目大纲如下:
一、问题描述
基于训练集数据,训练一个模型,利用训练好的模型预测未知图片中的动物是狗或者猫的概率。
训练集有25,000张图片,测试集12,500 张图片。
数据集下载地址:https://www.kaggle.com/datasets/shaunthesheep/microsoft-catsvsdogs-dataset

二、数据集处理
1 损坏图片清洗
在 01_clean.py中,用多种方式来清洗损坏图片:
- 判断开头是否有JFIF
- 用imghdr库中的imghdr.what函数判断文件类型
- 用Image.open(filename).verify()验证图片是否损坏
结果如下:

2 抽取图片形成数据集
由于一万多张图片比较多,并且需要将Cat类和Dog类的图片合在一起并重新命名,方便获得每张图片的labels,所以可以从原图片文件夹复制任意给定数量图片到train的文件夹,并且重命名如下:

程序为:02_data_processing.py.
三、图片预处理
图片预处理部分需要完成:
- 对图片的裁剪:将大小不一的图片裁剪成神经网络所需的,我选择的是裁剪为(224x224)
- 转化为张量
- 归一化:三个方向归一化
- 图片数据增强
- 形成加载器:返回图片数据和对应的标签,利用Pytorch的Dataset包
在 dataset.py中定义Mydata的类,继承pytorch的Dataset,定义如下三个方法:
(1)init 方法
读取图片路径,并拆分为数据集和验证集(以下代码仅体现结构,具体见源码):
class Mydata(data.Dataset):
"""定义自己的数据集"""
def __init__(self, root, Transforms=None, train=True):
"""进行数据集的划分"""
if train:
self.imgs = imgs[:int(0.8*imgs_num)] #80%训练集
else:
self.imgs = imgs[int(0.8*imgs_num):] #20%验证集
"""定义图片处理方式"""
if Transforms is None:
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])
self.transforms = transforms.Compose(
[ transforms.CenterCrop(224),
transforms.Resize([224,224]),
transforms.ToTensor(), normalize])(2)getitem方法
对图片处理,返回数据和标签:
def __getitem__(self, index):
return data, label(3)len方法
返回数据集大小:
def __len__(self):
"""返回数据集中所有图片的个数"""
return len(self.imgs)(4)测试
实例化数据加载器后,通过调用getitem方法,可以得到经过处理后的$3\times244\times244$的图片数据
if __name__ == "__main__":
root = "./data/train"
train = Mydata(root, train=True) #实例化加载器
img,label=train.__getitem__(5) #获取index为5的图片
print(img.dtype)
print(img.size(),label)
print(len(train)) #数据集大小
#输出
torch.float32
torch.Size([3, 224, 224]) 0
3200裁剪处理后图片如下所示,大小为224X224:
四、模型
模型都放在 models.py中,主要用了一些经典的CNN模型:
- LeNet
- ResNet
- ResNet
- SqueezeNet
下面给出重点关注的LeNet模型和AlexNet模型:
1 LeNet
LeNet模型是一个早期用来识别手写数字图像的卷积神经网络,这个名字来源于LeNet论文的第一作者Yann LeCun。LeNet展示了通过梯度下降训练卷积神经网络可以达到手写数字识别在当时最先进的结果,LeNet模型结构图示如下所示:
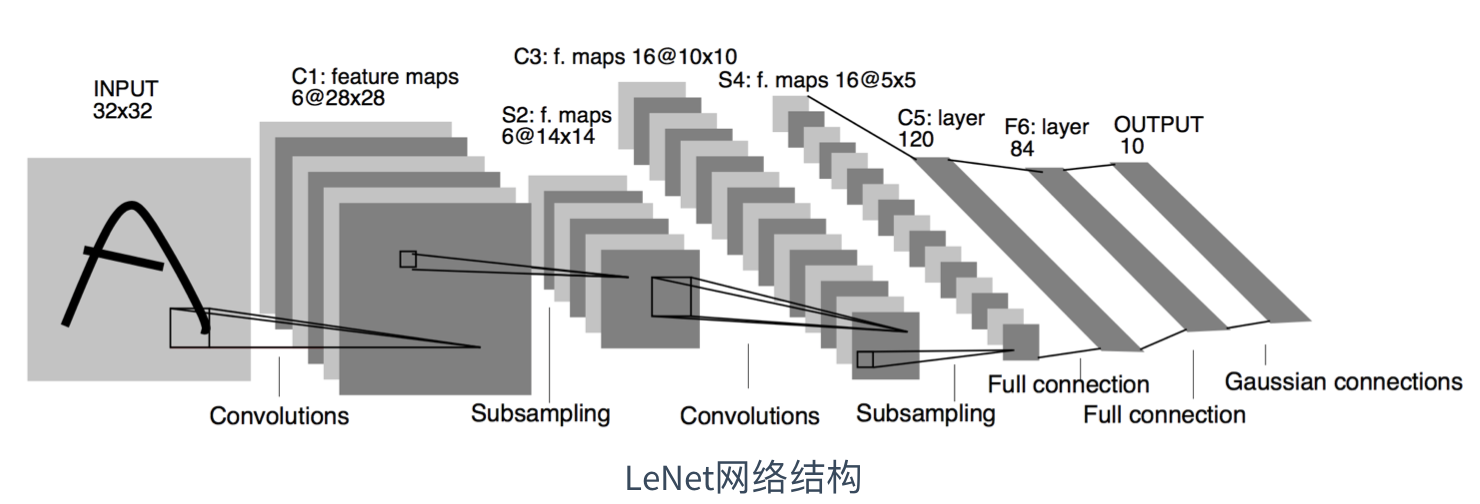
由上图知,LeNet分为卷积层块和全连接层块两个部分,在本项目中我对LeNet模型做了相应的调整:
- 采用三个卷积层
- 三个全连接层
- ReLu作为激活函数
- 在卷积后正则化
class LeNet(nn.Module):
def __init__(self):
super(LeNet, self).__init__()
self.relu = nn.ReLU()
self.sigmoid = nn.Sigmoid()
#三个卷积层
self.conv1 = nn.Sequential(
nn.Conv2d(
in_channels=3,
out_channels=16,
kernel_size=3,
stride=2,
),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.conv2 = nn.Sequential(
nn.Conv2d(
in_channels=16,
out_channels=32,
kernel_size=3,
stride=2,
),
nn.BatchNorm2d(32),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
self.conv3 = nn.Sequential(
nn.Conv2d(
in_channels=32,
out_channels=64,
kernel_size=3,
stride=2,
),
nn.BatchNorm2d(64),
nn.ReLU(),
nn.MaxPool2d(kernel_size=2),
)
#三个全连接层
self.fc1 = nn.Linear(3 * 3 * 64, 64)
self.fc2 = nn.Linear(64, 10)
self.out = nn.Linear(10, 2) #分类类别为2,
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = x.view(x.shape[0], -1)
x = self.relu(self.fc1(x))
x = self.relu(self.fc2(x))
x = self.out(x)
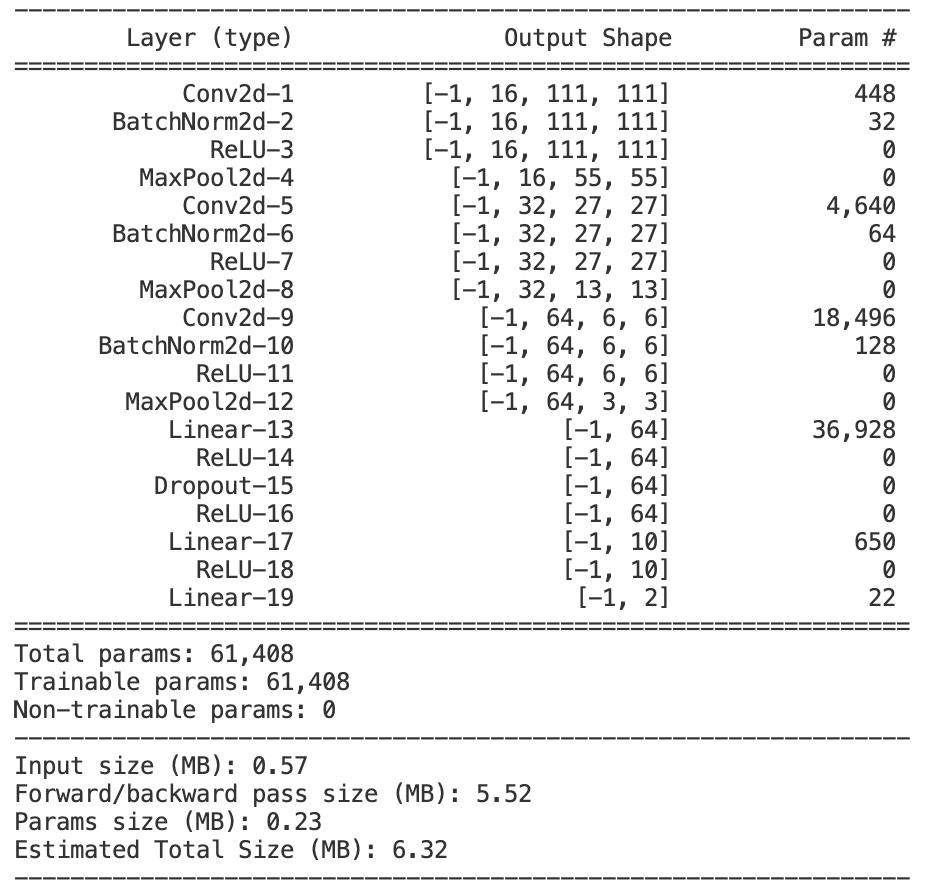
return x调用torchsummary库,可以观察模型的结构、参数:
2 AlexNet模型
2012年,AlexNet横空出世,这个模型的名字来源于论文第一作者的姓名Alex Krizhevsky。AlexNet使用了8层卷积神经网络,由5个卷积层和3个池化Pooling 层 ,其中还有3个全连接层构成。AlexNet 跟 LeNet 结构类似,但使⽤了更多的卷积层和更⼤的参数空间来拟合⼤规模数据集 ImageNet,它是浅层神经⽹络和深度神经⽹络的分界线。
特点:
- 在每个卷积后面添加了Relu激活函数,解决了Sigmoid的梯度消失问题,使收敛更快。
- 使用随机丢弃技术(dropout)选择性地忽略训练中的单个神经元,避免模型的过拟合(也使用数据增强防止过拟合)
- 添加了归一化LRN(Local Response Normalization,局部响应归一化)层,使准确率更高。
- 重叠最大池化(overlapping max pooling),即池化范围 z 与步长 s 存在关系 z>s 避免平均池化(average pooling)的平均效应
五、训练
训练在 main.py中,主要是对获取数据、训练、评估、模型的保存等功能的整合,能够实现以下功能:
- 指定训练模型、epoches等基本参数
- 是否选用预训练模型
- 接着从上次的中断的地方继续训练
- 保存最好的模型和最后一次训练的模型
- 对模型的评估:Loss和Accuracy
- 利用TensorBoard可视化
1 开始训练
在 main.py程序中,设置参数和模型(models.py中可以查看有哪些模型):

在vscode中点击运行或在命令行中输入:
python3 main.py即可开始训练,开始训练后效果如下:
若程序中断,设置resume参数为True,可以接着上次的模型继续训练,可以非常方便的任意训练多少次。
2 tensorboard可视化
在vscode中打开tensorboard,或者在命令行中进入当前项目文件夹下输入
tensorboard --logdir runs即可打开训练中的可视化界面,可以很方便的观察模型的效果:

如上图所示,可以非常方便的观察任意一个模型训练过程的效果!
六、不同模型训练结果分析
1 LeNet模型
在用LeNet模型训练的过程中,通过调整数据集数量、是否用数据增强等不同的方法,来训练模型,并观察模型的训练效果。
(1) 数据集数量=1000,无数据增强
通过Tensorboard可视化可以观察到:
- 验证集准确率(Accuracy)在上升,训练30epoch左右,达到最终63%左右的最好效果
- 但验证集误差(Loss)也在上升,训练集误差一直下降
- 训练集误差接近于0
说明模型在训练集上效果好,验证集上效果不好,泛化能力差,可以推测出模型过拟合了。而这个原因也是比较好推测的,数据集比较少。

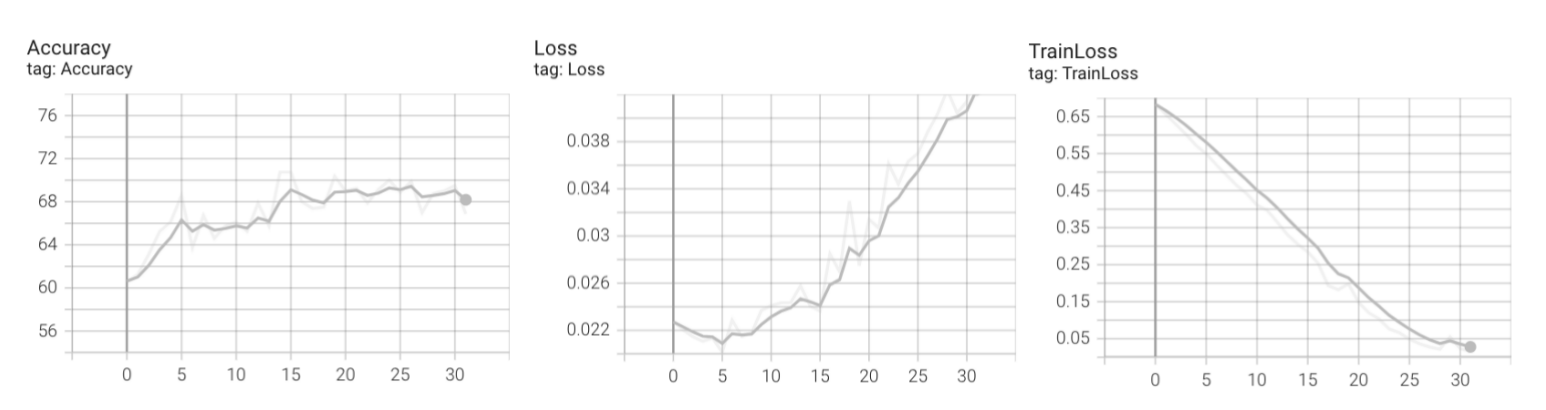
(2) 数据集数量=4000,无数据增强
同样过拟合了,但是最后的准确率能达到68%左右,说明数据集增加有效果
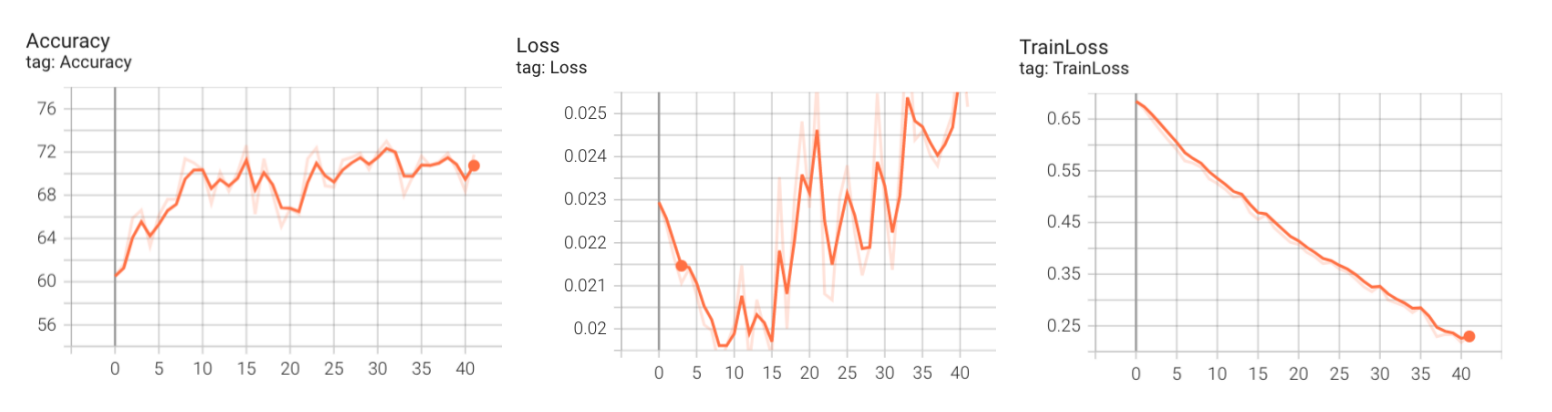
(3)数据集数量=4000,数据增强
这次数据集数量同上一个一样为4000,但采用了如下的数据增强:
- 水平翻转,概率为p=0.5
- 上下翻转,概率为p=0.1
我们可以看到这次一开始验证集误差是下降的,说明一开始没有过拟合,但到15个epoch之后验证集误差开始上升了,说明已经开始过拟合了,但最后的准确率在71%左右,说明数据增强对扩大数据集有明显的效果。
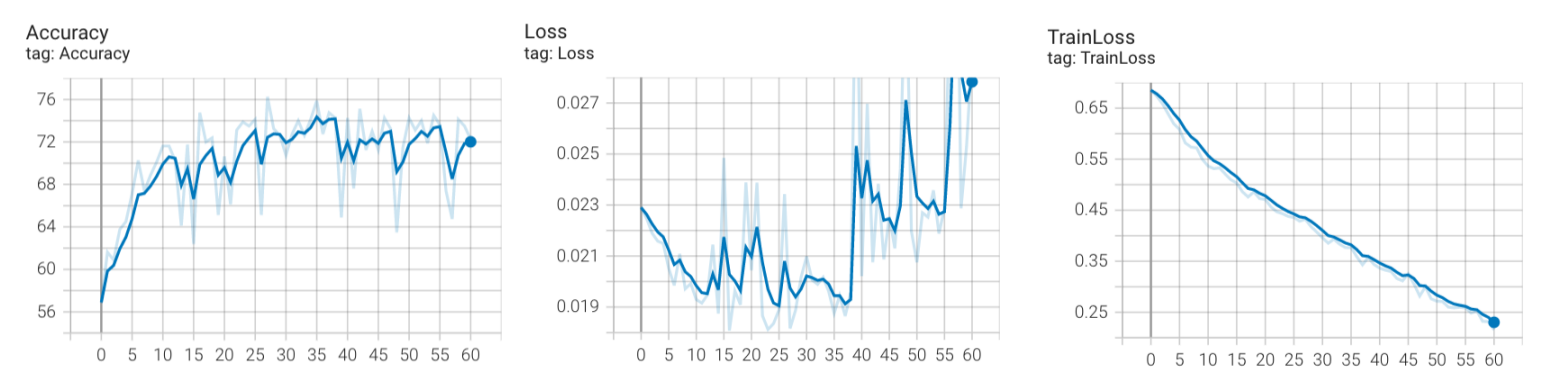
(4)数据集=4000,数据增强
这次数据集数量为4000,但采用了如下的数据增强:
- 水平翻转,概率为p=0.5
- 上下翻转,概率为p=0.5
- 亮度变化


可以看到:
- 35个epoch之前,验证集误差呈下降趋势,准确率也一直上升,最高能到75%。
- 但在35个epoch之后,验证集误差开始上升,准确率也开始下降
说明使用了更强的数据增强之后,模型效果更好了。
(5)使用dropout函数抑制过拟合
本次数据集和数据增强方式同(4),但是在模型的第一个全连接层加入dropout函数。
dropout原理:
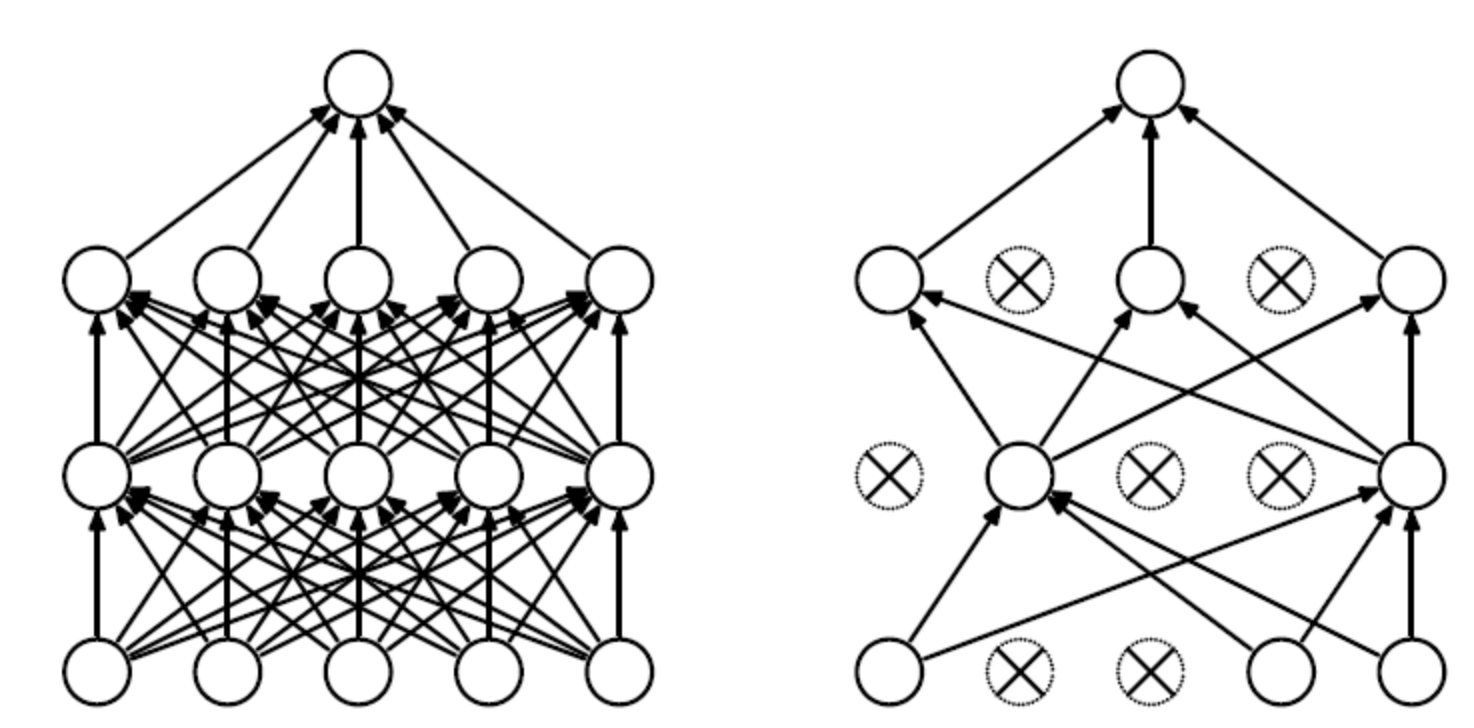
训练过程中随机丢弃掉一些参数。在前向传播的时候,让某个神经元的激活值以一定的概率p(伯努利分布)停止工作,这样可以使模型泛化性更强。
不使用dropout示意图 使用dropout示意图
这样相当于每次训练的是一个比较"瘦"的模型,更不容易过拟合
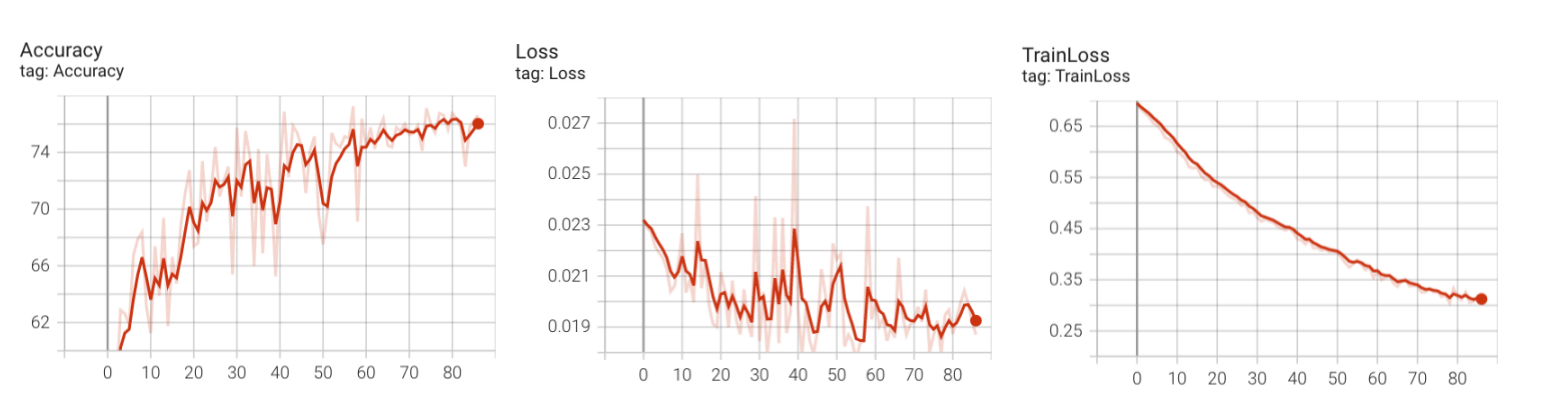
加入dropout函数后,训练85个epochs,可以观察到效果十分显著:
- 验证集的误差总体呈现下降趋势,且最后没有反弹!
- 训练集误差下降比较慢了!
- 准确率一直上升,最后可以达到76%!
说明模型最后没有过拟合,并且效果还不错。
2 AlexNet模型
将AlexNet模型参数打印出来:
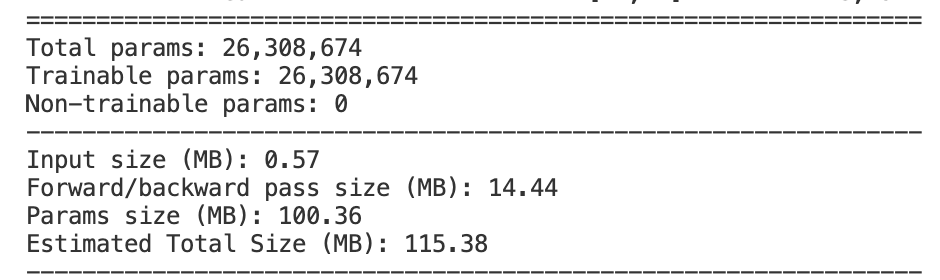
可以看到AlexNet相比LeNet,参数数目有数量级的上升,而在数据量比较小的情况下,很容易梯度消失,经过反复的调试:
- 要在卷积层加入正则化
- 优化器选择SGD
- 学习率不能过大
才能避免验证集的准确率一直在50%
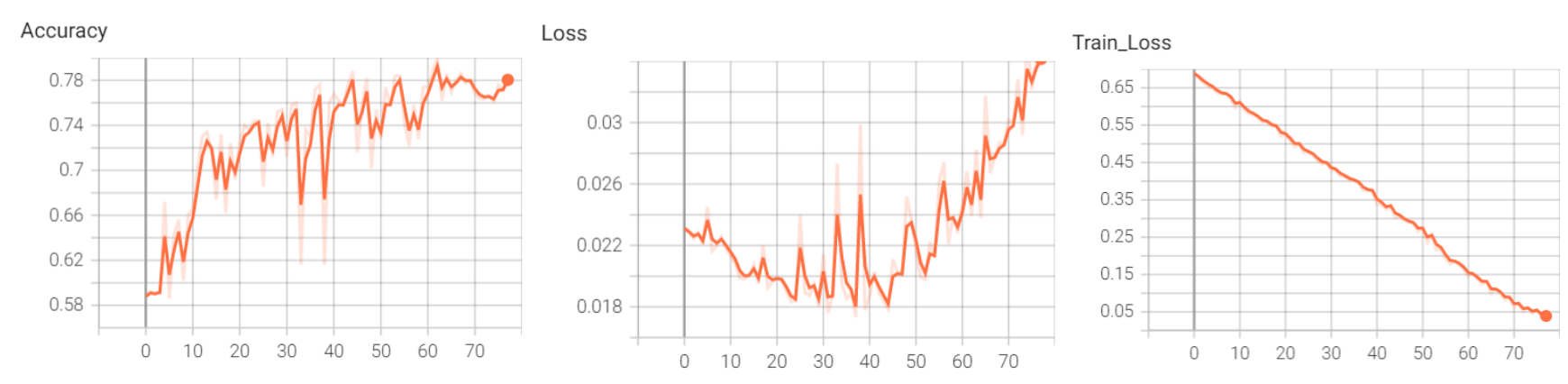
经过调试,较好的一次结果如下所示,最终准确率能达到78%
3 squeezeNet模型
在后面两个模型中,使用迁移学习的方法。
迁移学习(Transfer Learning)是机器学习中的一个名词,是指一种学习对另一种学习> 的影响,或习得的经验对完成其它活动的影响。迁移广泛存在于各种知识、技能与社会规范> 的学习中,将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。`
<img src="https://aurora-pics.oss-cn-beijing.aliyuncs.com/Pic/202402191620571.png" alt="截屏2022-04-29 下午11.58.32" style="zoom:70%;" />``
使用squeezeNet预训练模型,在迭代16个epoch后,准确率可以达到93%
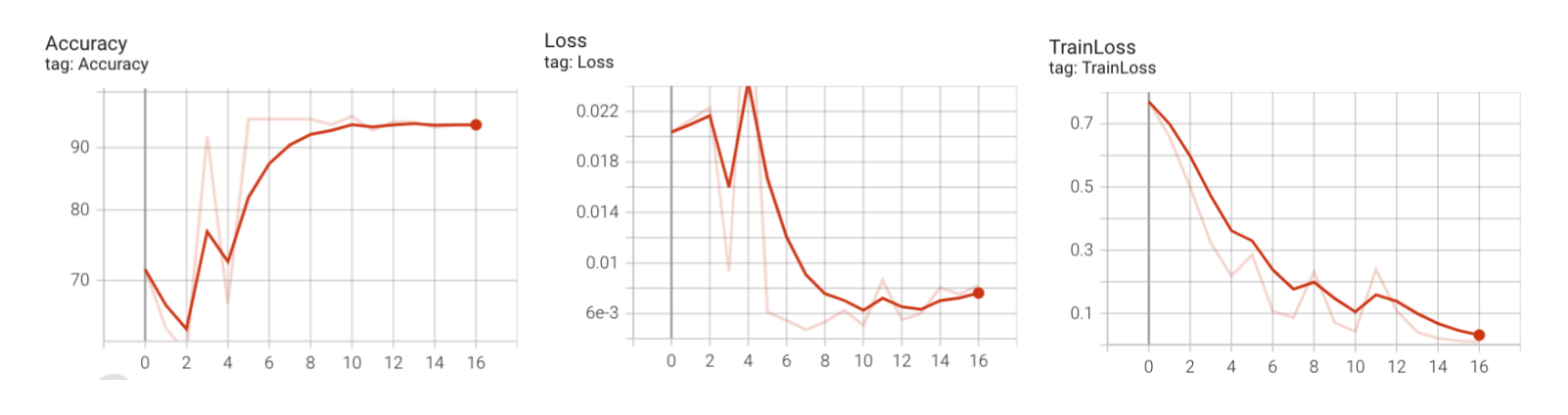
4 resNet模型
使用resnet50的预训练模型,训练25个epoch后,准确率可以达到98%!
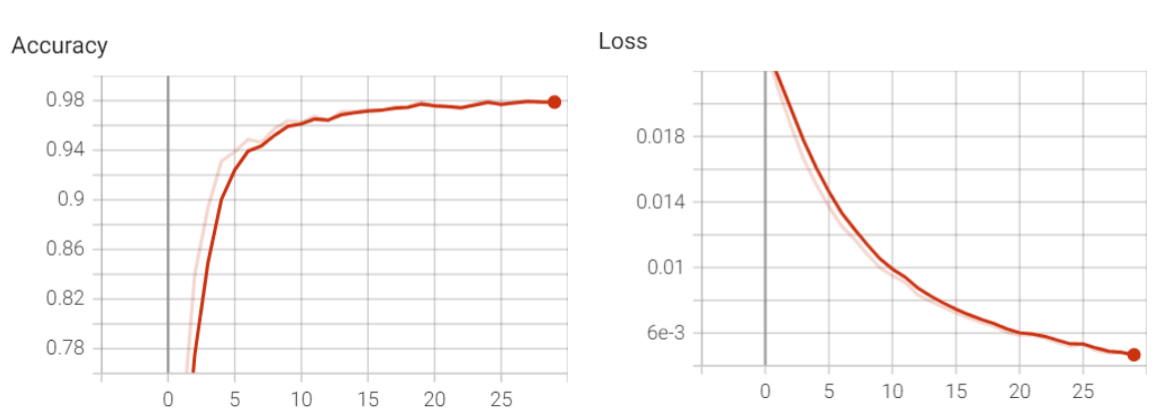
模型总结
| 模型 | 测试集预测准确率 |
|---|---|
| LeNet(无数据增强) | 68% |
| LeNet(数据增强) | 75% |
| LeNet(采用Dropout) | 76% |
| Alexnet | 78% |
| squeezeNet(迁移学习) | 93% |
| resNet | 98% |
七、预测
模型训练好后,可以打开 predict.py对新图片进行预测,给定用来预测的模型和预测的图片文件夹:
model = LeNet1() # 模型结构
modelpath = "./runs/LeNet1_1/LeNet1_best.pth" # 训练好的模型路径
checkpoint = torch.load(modelpath)
model.load_state_dict(checkpoint) # 加载模型参数
root = "test_pics"运行 predict.py 会将预测的图片储存在 output文件夹中,如下图所示:

会给出预测的类别和概率。