一、交叉验证
如果给定的样本数据充足,进行模型选择的一种简单方法是随机地将数据集切分成三部分,分别为训练集(training set)、验证集(validation set)和测试集(test set)。训练集用来训练模型,验证集用于模型的选择,而测试集用于最终对学习方法的评估。
但是,在许多实际应用中数据是不充足的。为了选择好的模型,可以采用交叉验证方法。交叉验证的基本想法是重复地使用数据,把给定的数据进行切分,将切分的数据集组合为训练集与测试集,在此基础上反复地进行训练、测试以及模型选择。
1 简单交叉验证
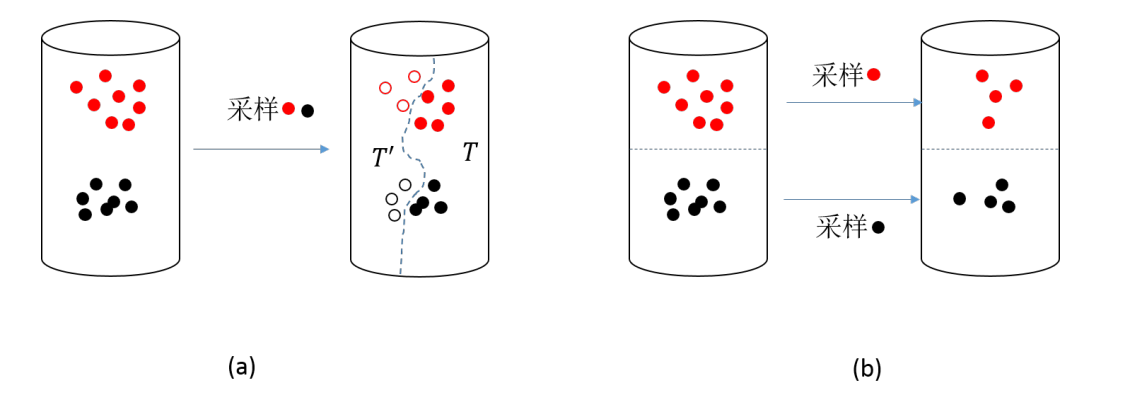
简单交叉验证方法是:将数据集 $D$ 随机划分为两个互不相交的子集,其中一个作为训练 集 $T$ ,另一个作为测试集 $T^{\prime}$ :
- 采用无放回的随机采样方式从数据集 $D$ 中抽出一部分数据 (设定的比例或个数)作为 $T$ ,剩下的数据作为 $T^{\prime}$.
- 要在采样中尽可能保持数据分布的一致性, 可采用分层无放回随机采样方式.
- 通常重复多次随机划分过程, 以每次划分对应的测试评估的均值作为评估结果.
2 K 折交叉验证
应用最多的是 K 折交叉验证(K-fold cross validation),方法如下:首先随机地将已给数据切分为 K个互不相交、大小相同的子集;然后利用 K − 1 个子集的数据训练模型,利用余下的子集测试模型;将这一过程对可能的 K 种选择重复进行;最后选出 K 次评测中平均测试误差最小的模型。
- 比较耗时,每轮要训练K次
3 留一交叉验证
K 折交叉验证的特殊情形是 K = N,称为留一交叉验证(leave-one-out cross validation),往往在数据缺乏的情况下使用。这里,N 是给定数据集的容量。
- 也就是说每次测试集只留一个数据
- 训练N次,数据量大时,计算开销大
二、自助法
自助法是为了解决交叉验证法在模型选择阶段训练集规模比整个样本小的问题,采用有放回抽样对交叉验证法进行改造。其具体策略如下:
- 先从 $D$ 中以有放回的抽样方式随机抽取 $|D|$ 个数据来构建训 练数据集 $T$,
- 然后以 $D$ 中没有被抽中的数据构建测试数据集 $T^{\prime}$.
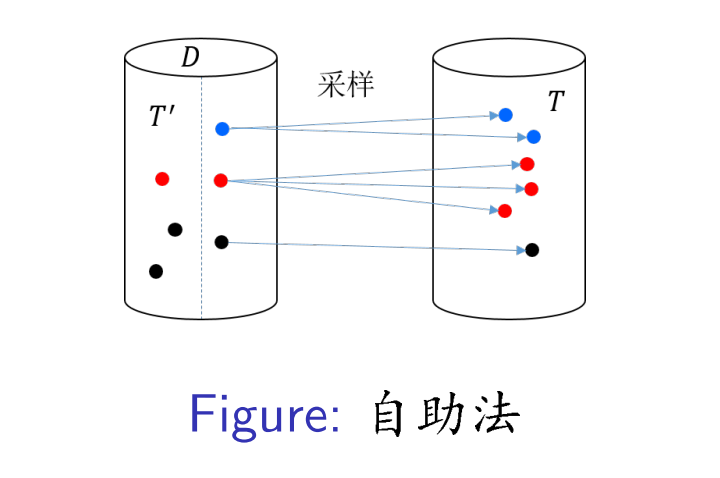
- 自助法解决了交叉验证法中模型选择阶段和最终模型训练阶段的训练集规模差异问题.
- 但训练集 $T$ 和原始数据集 $D$ 中数据的分布未必相一致, 因此对一些对数据分布敏感的模型选择并不话用.
三、异同
从上面对交叉验证法和自助法的介绍,我们可以发现它们之间的异同。
相同
- 都是机器学习中用于模型选择的方法;
- 模型选择阶段每次训练都只会用到样本的一部分.
不同
- 交叉验证法模型选择阶段和最终模型训练阶段的训练集规模不同;
- 自助法模型选择阶段和最终模型训练阶段的训练集规模相同;
- 自助法训练集数据分布可能域原始数据集数据分布不同.
Reference
- 《机器学习方法》,李航,2022.